1 实验目的
使用 Classification 中的 generative model 和 logistic regression,解决二分类问题。根据已有数据,判断该人年收入是否大于 50K。
2 实验环境
- 操作系统:windows 11
- CPU:AMD Ryzen 7 5800H with Radeon Graphics (3.20 GHz)
- GPU:NVIDIA GeForce GTX 1650
- 运行环境:
- Python 3.10.11
- pandas 2.1.0
- numpy 1.24.2
- matplotlib 3.7.1
- tqdm 4.66.1
3 数据处理
3.1 数据文件描述
-
train.csv / test.csv:包含 age, workclass, fnlwgt (总人数), education, education num, marital-status, occupation, relationship, race, sex, capital-gain, capital-loss, hours-per-week, native-country, make over 50K a year or not 这些特征。
-
X_train / X_test:包含 106-dim 的特征的数据,是将 train.csv 进行 one-hot Encoding(独热编码)之后的数据,将分类向量转化为了二进制向量。
-
Y_train:包含 1-dim 标签的数据,1 表示 make over 50K a year,0 表示 not make over 50K a year.
3.2 读取数据
在 data_manager 类中有读取数据的函数 read():
def read(self,name,path):
with open(path,newline = '') as csvfile:
# 读取数据,从第二行开始读取
rows = np.array(list(csv.reader(csvfile))[1:] ,dtype = float)
3.3 数据预处理
3.3.1 对训练数据进行标准化
$$ \sigma = \sqrt{\frac{1}{N}\sum_{i=1}^{N}(x_i-\mu)^2}\ z_i = \frac{x_i-\mu}{\sigma} $$
这样可以使多组数据的均值为 0,方差为 1,使数据标准统一化。
if name == 'X_train':
self.mean = np.mean(rows,axis = 0).reshape(1,-1)
self.std = np.std(rows,axis = 0).reshape(1,-1)
self.theta = np.ones((rows.shape[1] + 1,1),dtype = float) #初始化参数
for i in range(rows.shape[0]):
rows[i,:] = (rows[i,:] - self.mean) / self.std #标准化
# 注意,testing data要跟training data的normalize方式一致,要用training data的mean和std
elif name == 'X_test':
for i in range(rows.shape[0]):
rows[i,:] = (rows[i,:] - self.mean) / self.std #标准化
4 概率生成模型(generative model)
4.1 公式推导
4.1.1 贝叶斯定理
根据条件概率: $$ P(x,y)=P(x|y)P(y) $$ 其中,$P(x|y)$ 是数据 $x$ 在给定标签 $y$ 下的条件概率,而 $P(y)$ 是标签 $y$ 的先验概率。
贝叶斯定理: $$ P(y|x)=\frac{P(x|y)P(y)}{P(x)} $$ 其中 $P(y|x)$ 是后验概率,$P(x)$ 是数据的边际条件。
4.1.2 高斯分布
高斯分布概率密度函数为: $$ P(x) = \frac{1}{(2\pi)^{d/2} |\Sigma|^{1/2}} \exp \left( -\frac{1}{2} (x - \mu)^T \Sigma^{-1} (x - \mu) \right) $$
$$ \ln \left( \frac{P(C_1 | x)}{P(C_0 | x)} \right) = \ln \left( \frac{P(x | C_1) P(C_1)}{P(x | C_0) P(C_0)} \right)= \ln P(x | C_1) - \ln P(x | C_0) + \ln \frac{P(C_1)}{P(C_0)} $$
将上面的判别函数带入高斯分布的密度函数: $$ = -\frac{1}{2} (x - \mu_1)^T \Sigma^{-1} (x - \mu_1) + \frac{1}{2} (x - \mu_0)^T \Sigma^{-1} (x - \mu_0) + \ln \frac{n_1}{n_0} $$ 所以我们得到了判别函数: $$ f(x) = x^T \Sigma^{-1} (\mu_1 - \mu_0) - \frac{1}{2} (\mu_1^T \Sigma^{-1} \mu_1 - \mu_0^T \Sigma^{-1} \mu_0) + \ln \frac{n_1}{n_0} $$
4.2 代码实现
4.2.1 对数据进行二分类
我们需要先根据 Y_train 中的数据,也就是根据年收入是否大于 5 万元,记录对应的下标。
class_0_id = []
class_1_id = []
for i in range(self.data['Y_train'].shape[0]): # 对数据进行分类
if self.data['Y_train'][i][0] == 0:
class_0_id.append(i)
else:
class_1_id.append(i)
class_0 = self.data['X_train'][class_0_id]
class_1 = self.data['X_train'][class_1_id]
4.2.2 计算均值和协方差
$$ \mu_ = \frac{1}{n}\sum_{i=0}^{n} x_i \ \sigma = \frac{1}{n} \sum_{i=0}^{n}(x_i -\mu)(x_i-\mu)^T $$
mean_0 = np.mean(class_0, axis=0) # 分别计算两类的均值
mean_1 = np.mean(class_1, axis=0)
n = class_0.shape[1]
cov_0 = np.zeros((n, n))
cov_1 = np.zeros((n, n))
n_0 = class_0.shape[0]
n_1 = class_1.shape[0]
for i in range(class_0.shape[0]): # 计算协方差矩阵
# please add code here
cov_0 += np.dot(np.transpose([class_0[i]-mean_0]),
[class_0[i]-mean_0]) / n_0
for i in range(class_1.shape[0]):
cov_1 += np.dot(np.transpose([class_1[i]-mean_1]),
[class_1[i]-mean_1]) / n_1
然后我们需要合并这两个协方差矩阵,采用加权平均的方式。 $$ \Sigma = \frac{n_1 \sigma_1+n_2 \sigma_2}{n_1+n_2} $$
cov = (n_0*cov_0+n_1*cov_1)/(n_0+n_1) # 计算协方差矩阵,使用加权的方法
cov_inv = inv(cov)
4.2.3 计算参数权重向量和偏置项
根据 Gaussian Distribution,将 Gaussian Distribution 代入 Sigmoid 函数 ,我们可以得到 $P(C_1|x)=\sigma(w \cdot x+b)$ ,我们需要计算出权重向量 w 和偏置项 b。
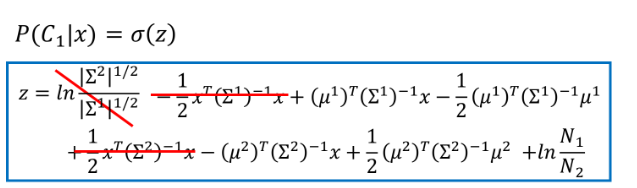
化简得到: $$ w= \Sigma ^{-1}(\mu_1 - \mu_0) $$ $$ b=-\frac{1}{2}(\mu_1^T\Sigma^{-1}\mu_1-\mu_0^T\Sigma^{-1}\mu_0)+ln \frac{n_1}{n_0} $$
self.w = np.dot((mean_0-mean_1).transpose(),
cov_inv).transpose() # 计算w
self.b = (-0.5)*np.dot(np.dot(mean_0.transpose(), cov_inv), mean_0)+0.5 * \
np.dot(np.dot(mean_1.transpose(), cov_inv),mean_1)+np.log(float(n_0)/n_1) # 计算b
4.2.4 Sigmoid 函数
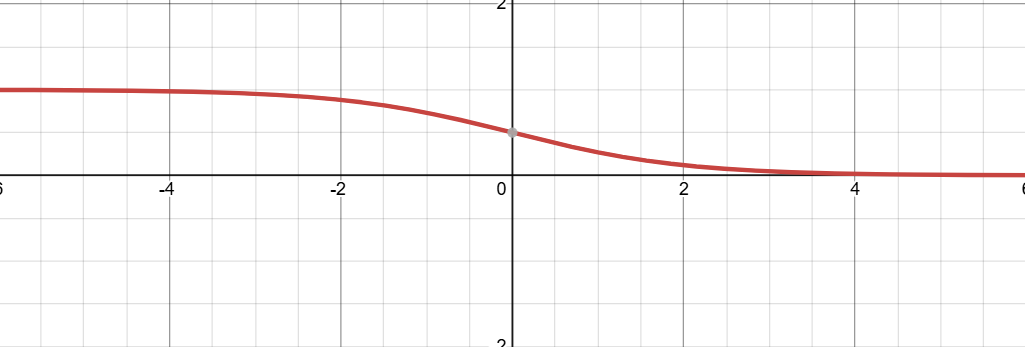 $$
\sigma(z)=\frac{1}{1+e^{-z}}
$$
将 $z=w \cdot x+b$ 代入 sigmoid 函数,我们可以得到 $C_1$ 的后验概率 $P(C_1|x)=\sigma(w \cdot x+b)$ ,我们就可以根据这个概率来进行分类了,可以发现,Sigmoid函数的值域是 $(0,1)$,根据大于/小于 0.5 进行二分类。
$$
\sigma(z)=\frac{1}{1+e^{-z}}
$$
将 $z=w \cdot x+b$ 代入 sigmoid 函数,我们可以得到 $C_1$ 的后验概率 $P(C_1|x)=\sigma(w \cdot x+b)$ ,我们就可以根据这个概率来进行分类了,可以发现,Sigmoid函数的值域是 $(0,1)$,根据大于/小于 0.5 进行二分类。
def func(self, x):
arr = np.empty([x.shape[0], 1], dtype=float)
for i in range(x.shape[0]):
z = x[i, :].dot(self.w) + self.b
z *= (-1)
arr[i][0] = 1 / (1 + np.exp(z))
return np.clip(arr, 1e-8, 1-(1e-8))
4.2.5 predict 预测函数
根据公式 $P(C_1|x)=\sigma(w \cdot x+b)$ 计算出的概率,大于0.5设为 0,小于0.5设为 1。
def predict(self, x):
ans = np.ones([x.shape[0], 1], dtype=int)
for i in range(x.shape[0]):
if x[i] > 0.5:
ans[i] = 0
return ans
4.2.6 计算准确率
我们使用 X_train 进行预测,并使用 Y_train 的正确结果进行验证,从而计算出 acc。
def accuracy(self, x, y): # 根据训练数据计算准确率
result = self.func(x)
answer = self.predict(result)
return 1 - np.mean(np.abs(answer-y))
4.2.7 将预测结果写入文件
def write_file(self, path): #预测测试数据并将结果写入文件
result = self.func(self.data['X_test'])
answer = self.predict(result)
with open(path, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['id', 'label'])
for i in range(answer.shape[0]):
writer.writerow([i+1, answer[i][0]])
预测结果:

5 逻辑回归(Logistic Regression)
5.1 公式推导
5.1.1 Logistic Regression 的前提
假设我们有一组数据集 $(X, Y)$,其中:
- $X \in \mathbb{R}^{m \times n}$:包含 $m$ 个样本,每个样本有 $n$ 个特征。
- $Y \in {0, 1}^m$:对应的分类标签,取值为 $0$ 或 $1$。 目标是学习一个模型,能够预测输入样本属于类 $1$ 的概率 $P(Y=1|X)$。
5.1.2 模型假设
逻辑回归假设: $$ P(Y=1|X) = \sigma(z) = \frac{1}{1 + e^{-z}} $$ 其中:
-
$z = w^T X + b$:是线性组合,$w \in \mathbb{R}^n$ 是权重向量,$b$ 是偏置。
-
$\sigma(z)$ 是 sigmoid 函数,将任意实数映射到区间 $[0, 1]$。 因此,逻辑回归模型可以表示为: $$ P(Y=1|X) = \frac{1}{1 + e^{-(w^T X + b)}} $$
5.1.3 Loss 函数:最大似然估计
假设所有样本是独立同分布的,联合概率可以表示为: $$ P(Y|X; w, b) = \prod_{i=1}^m \Big(P(y^{(i)}|x^{(i)})\Big) $$ 其中 $y^{(i)} \in {0, 1}$ 是第 $i$ 个样本的标签。
将 $P(y^{(i)}|x^{(i)})$ 写成通式: $$ P(y^{(i)}|x^{(i)}) = \sigma(z^{(i)})^{y^{(i)}} \cdot (1 - \sigma(z^{(i)}))^{1 - y^{(i)}} $$ 因此,联合概率的对数似然函数为: $$ \ell(w, b) = \sum_{i=1}^m \Big(y^{(i)} \log(\sigma(z^{(i)})) + (1 - y^{(i)}) \log(1 - \sigma(z^{(i)}))\Big) $$ 其中 $z^{(i)} = w^T x^{(i)} + b$。
为了优化方便,最小化负对数似然,其表达式为: $$ J(w, b) = -\ell(w, b) = -\frac{1}{m} \sum_{i=1}^m \Big(y^{(i)} \log(\sigma(z^{(i)})) + (1 - y^{(i)}) \log(1 - \sigma(z^{(i)}))\Big) $$ 这被称为二分类的交叉熵损失函数(Cross-Entropy Loss)。
5.1.4 梯度下降优化
为了最小化损失函数 $J(w, b)$,使用梯度下降法更新参数 $w$ 和 $b$。梯度计算如下:
- 对 $w$ 的梯度:
$$ \frac{\partial J(w, b)}{\partial w} = \frac{1}{m} \sum_{i=1}^m (h^{(i)} - y^{(i)}) x^{(i)} $$
其中 $h^{(i)} = \sigma(w^T x^{(i)} + b)$。
- 对 $b$ 的梯度:
$$ \frac{\partial J(w, b)}{\partial b} = \frac{1}{m} \sum_{i=1}^m (h^{(i)} - y^{(i)}) $$
- 梯度更新公式:
$$ w = w - \alpha \frac{\partial J(w, b)}{\partial w} \ b = b - \alpha \frac{\partial J(w, b)}{\partial b} $$
其中 $\alpha$ 是学习率。
5.2 代码实现
5.2.1 标准化 normalize
和 generative model 一致。
def normalize(X, mean=None, std=None):
mean = np.mean(X, axis=0).reshape(1, -1) # 将每一行的元素相加求均值,实际上返回的是1行106列的数组
std = np.std(X, axis=0).reshape(1, -1) # 将每一行的元素相加求标准差,实际上返回的是1行106列的数组
X = (X - mean) / std # 标准化
return X, mean, std
X_train, mean, std = normalize(X_train) # 标准化
X_test = (X_test - mean) / std # 使用训练集的均值和方差对测试集进行标准化
5.2.2 对训练数据进行划分
X_train 中 80% 作为训练集,20% 作为验证集。
def train_data_split(X, Y, ratio=0.8): # 对训练集进行划分
size = int(X.shape[0] * ratio)
return X[:size], Y[:size], X[size:], Y[size:]
X_train, Y_train, X_val, Y_val = train_data_split(X_train, Y_train)
# 输出数据的大小和维度
print("Size of X_train: {}".format(X_train.shape[0]))
print("Size of X_val: {}".format(X_val.shape[0]))
print("Size of X_test: {}".format(X_test.shape[0]))
print("Dimension of X_train: {}".format(X_train.shape[1]))

5.2.3 对数据进行打乱
将数据按行打乱,这样可以保证数据的随机性。
def shuffle(X, Y): # 对数据进行打乱
np.random.seed(0)
randomize = np.arange(X.shape[0])
np.random.shuffle(randomize)
return X[randomize], Y[randomize]
5.2.4 Loss 函数
根据交叉熵损失函数的公式: $$ J(w, b) = -\ell(w, b) = -\frac{1}{m} \sum_{i=1}^m \Big(y^{(i)} \log(\sigma(z^{(i)})) + (1 - y^{(i)}) \log(1 - \sigma(z^{(i)}))\Big) $$
def cross_entropy_loss(y_pred, Y_label):
cross_entropy = -np.mean(
Y_label * np.log(y_pred) + (1 - Y_label) * np.log(1 - y_pred)
)
return cross_entropy
5.2.5 计算梯度
根据梯度计算公式: $$ w_{grad}=\frac{\partial J(w, b)}{\partial w} = \frac{1}{m} \sum_{i=1}^m (h^{(i)} - y^{(i)}) x^{(i)} \ b_{grad}=\frac{\partial J(w, b)}{\partial b} = \frac{1}{m} \sum_{i=1}^m (h^{(i)} - y^{(i)}) $$
def gradient(X, Y_label, w, b): # 计算梯度
y_pred = f(X, w, b)
pred_error = Y_label - y_pred
w_grad = -np.dot(pred_error, X)
b_grad = -np.sum(pred_error)
return w_grad, b_grad
5.2.6 训练
训练模型时,采用 Mini-Batch Gradient Descent 和 Adagrad 这两种梯度下降法。
- Mini-Batch Gradient Descent:
- 结合了随机梯度下降(SGD)和全梯度下降的优点。
- 每次更新使用一小部分数据,计算速度较快,具有一定的噪声引入效果,有助于跳出局部极值。
- Adagrad :
- 可以动态的调整学习率。
# 开始训练
Y_train = Y_train.flatten() # 将Y_train展平
Y_val = Y_val.flatten() # 将Y_val展平
w = np.zeros((X_train.shape[1],)) # 初始化w
b = np.zeros((1,)) # 初始化b
iter = 20 # 迭代次数
batch_size = 8 # 批次大小
learning_rate = 0.1 # 学习率
train_loss = []
val_loss = []
train_acc = []
val_acc = []
count = 1
# 初始化累积梯度
w_accum_grad = np.zeros((X_train.shape[1],))
b_accum_grad = np.zeros((1,))
for epoch in tqdm(range(iter)):
X_train, Y_train = shuffle(X_train, Y_train)
# 每次取batch_size个数据进行训练
for idx in range(int(np.floor(X_train.shape[0] / batch_size))):
X = X_train[idx * batch_size:(idx + 1) * batch_size]
Y = Y_train[idx * batch_size:(idx + 1) * batch_size]
w_grad, b_grad = gradient(X, Y, w, b)
# 累积梯度平方和,adagrad
w_accum_grad += w_grad**2
b_accum_grad += b_grad**2
# 更新w和b
w -= (learning_rate / np.sqrt(w_accum_grad + 1e-8)) * w_grad
b -= (learning_rate / np.sqrt(b_accum_grad + 1e-8)) * b_grad
5.3 实验结果

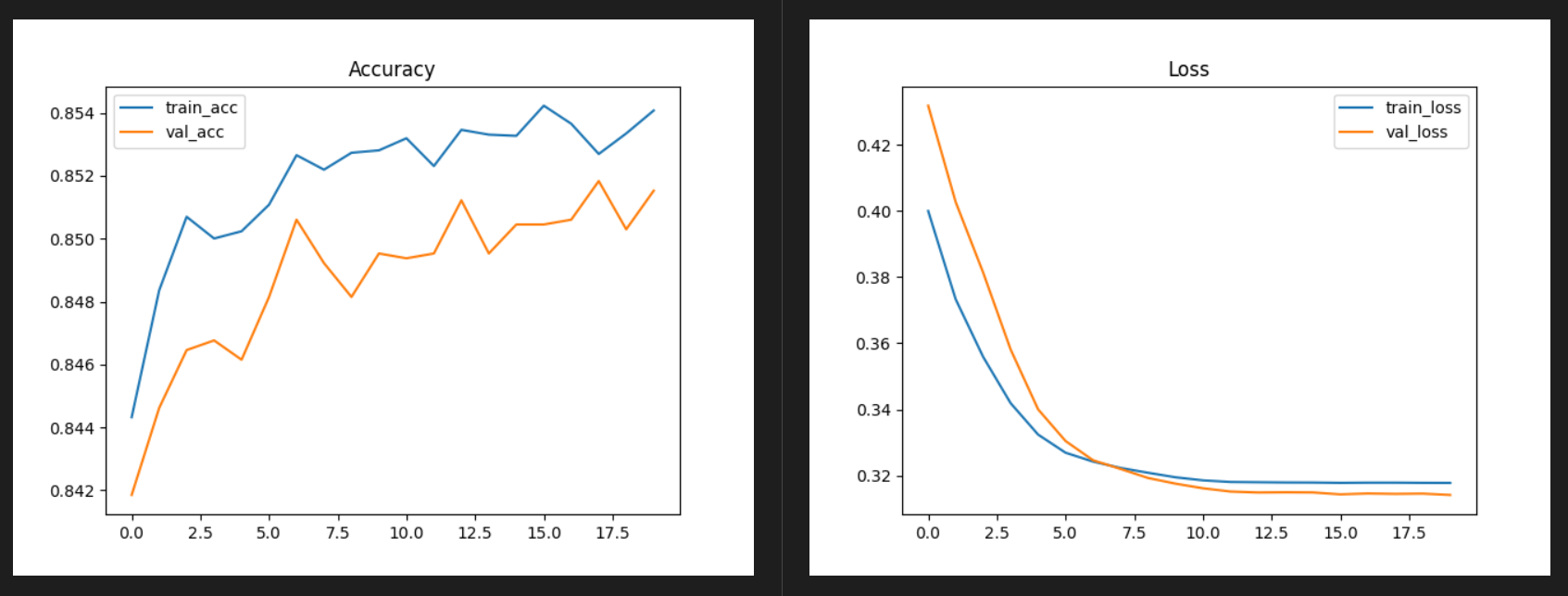
6 实验评估
6.1 Accuracy
准确率方面,Logistic Regression 要略优于 Generative Model。
-
Logistic Regression:
-
逻辑回归是 判别模型,直接建模 P(Y∣X),即条件概率分布。它的目标是通过最大化数据点的对数似然,直接优化分类边界,专注于如何在给定特征 X 下预测 Y。
-
不关心特征 X 的分布,因此对于 X 分布的假设较少,更灵活。
-
-
Generative Model:
-
生成模型通过建模联合概率分布 P(X, Y) 来推导条件概率 P(Y∣X)。它要求对 P(X∣Y) 和 P(Y) 分布做出明确的假设(如高斯分布)。
-
如果数据本身不符合假设(例如 P(X∣Y) 不是高斯分布),生成模型可能产生偏差,影响分类性能。
-
6.2 特征标准化对准确率的影响
- 未进行标准化:


- 进行标准化:
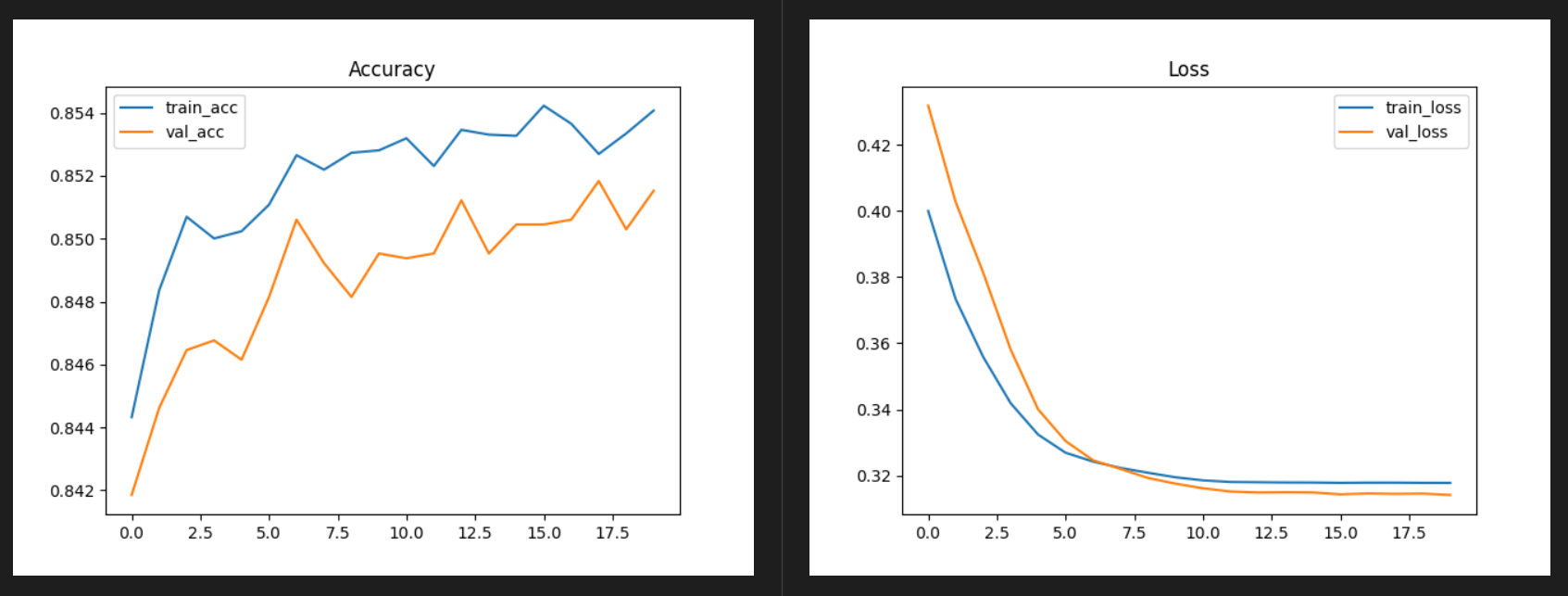
可以发现 acc 和 loss 的波动很大,而且几乎没有收敛的趋势,准确率也大大降低。
标准化可以统一不同数据的平均值和标准差,提高了数据可比性,削弱了数据解释性。
6.3 Logistic Regression 的正则化对模型准确率的影响
加入正则化后的损失函数: $$ Loss = CrossEntropyLoss+\frac{\lambda}{2}||w||^2 $$ 其中 $\lambda$ 是正则化系数。
$\lambda=0.1$ 时:
| 使用正则化 | 未使用正则化 | |
|---|---|---|
| train_acc | 0.8528101965601965 | 0.8540770884520885 |
| val_acc | 0.8483033932135728 | 0.8515277138031629 |
可以发现加入了正则化参数后,模型的准确率有些许的下降,这可能与我们选择 adagrad 梯度下降有关。
6.4 找到对结果影响最大的特征
# 找到影响最大的特征
with open('X_train', newline='') as csvfile:
featrues = list(csv.reader(csvfile))[0] # 通过表头获取特征名
max = np.max(np.abs(w)) # 获取绝对值最大的权重
for i in range(len(w)):
if abs(w[i]) == max:
print("The most important feature is: ",
featrues[i], "with weight: ", w[i])
# 找出前五个特征
top_5_indices = np.argsort(-np.abs(w))[:5]
print("Top 5 important features and their weights:")
for i in top_5_indices:
print(f"Feature: {featrues[i]}, Weight: {w[i]}")

