一、实验目的
利用即墨站的空气质量监测数据,使用线性回归(Linear Regression)预测 PM2.5 的数值。
二、实验环境
- 操作系统:Windows 11
- 处理器:AMD Ryzen 7 5800H with Radeon Graphics (3.20 GHz)
- 显卡:NVIDIA GeForce GTX 1650
- 运行环境:
- Python 3.10.11
- pandas 2.1.0
- numpy 1.24.2
- matplotlib 3.7.1
- tqdm 4.66.1
三、数据说明
1. 训练集(Train Set)
train.csv包含了 2014 年 1 月 1 日至 2014 年 12 月 20 日的即墨站的全部监测数据,使用 VScode 插件转成表格形式如下所示:
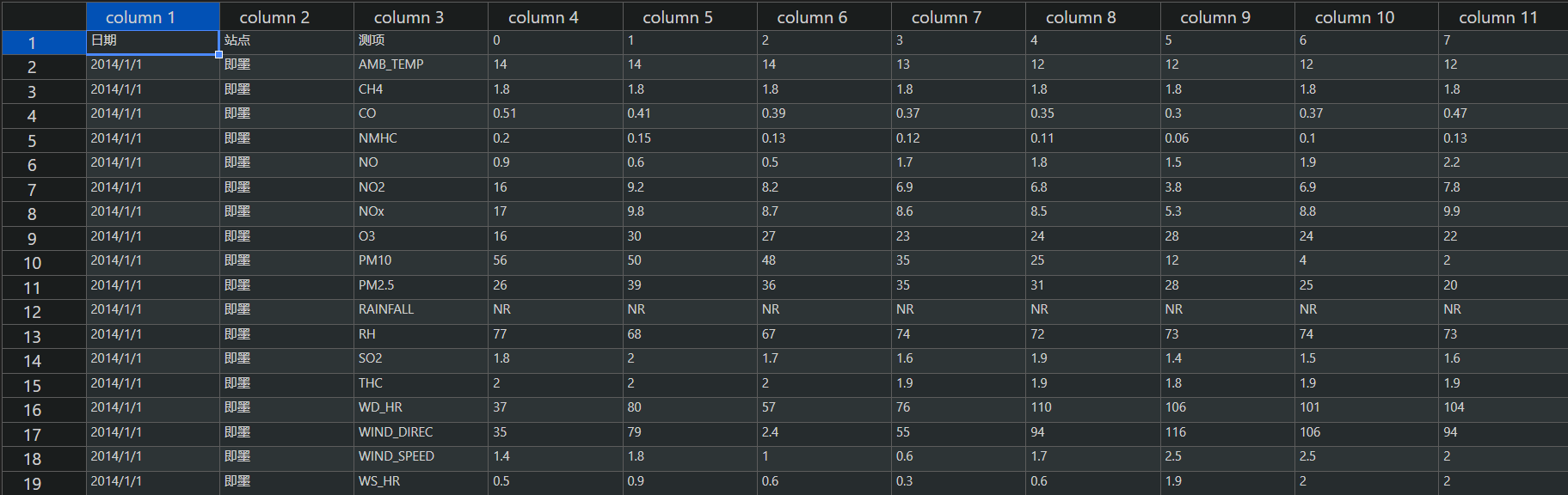
- 表头包含了日期、站点、测项以及24小时的监测数值
- 测项共有 18 项观测数据:AMB_TEMP, CH4, CO, NHMC, NO, NO2, NOx, O3, PM10, PM2.5, RAINFALL, RH, SO2, THC, WD_HR, WIND_DIREC, WIND_SPEED, WS_HR。
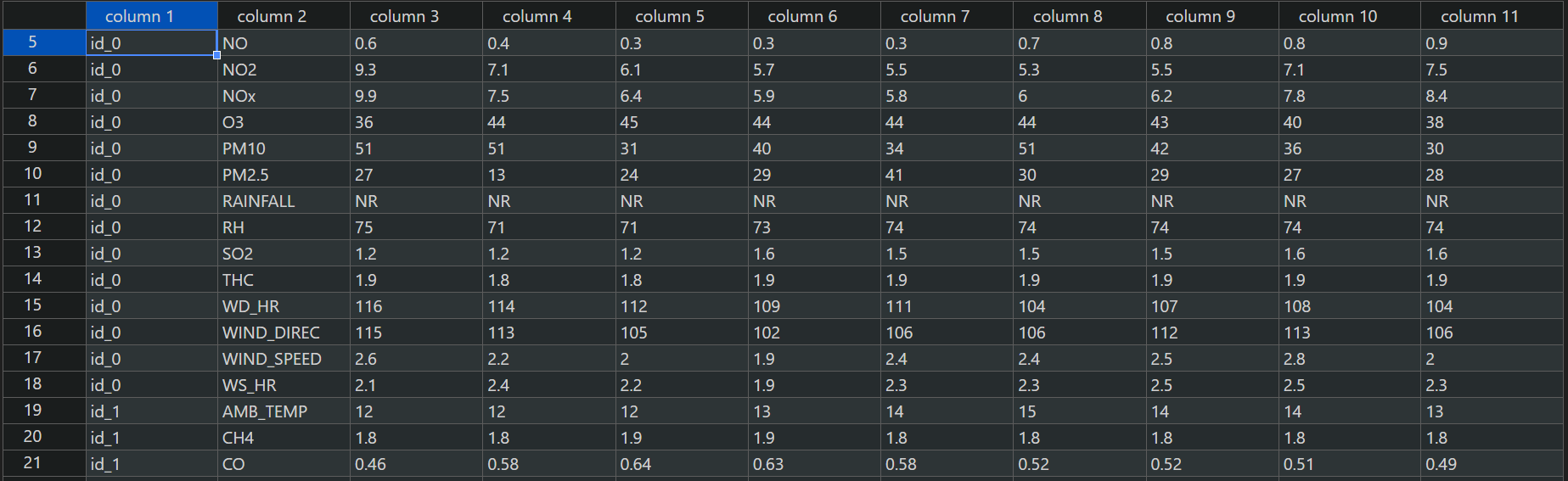
2. 测试集(Test Set)
test.csv是从剩下的数据中取出的连续的 10 小时作为一笔数据,前 9 小时作为 feature,第 10 小时的 PM2.5 数值作为 answer。
使用 VScode 插件转成表格形式如下所示:
四、实验方法
1. 导入必要的库
import pandas as pd # 用于读取 csv 文件
import numpy as np # 用于创建向量和进行数学统计
import matplotlib.pyplot as plt # 用于绘制图像
from tqdm import tqdm # 用于显示进度条
2. 数据预处理
-
将数据按月份分为 12 组,每组有 18 行,每行有 $20 \times 24 =480$ 小时的数据。
-
构建训练数据 x,x 为每个连续 9 小时的数据,共 $12 \times (480-9)=12 \times 471$ 组,每组有 $9 \times 18$ 个观测值。
-
构建标签数据 y,y 为每个第 10 小时的数据,共 $12 \times (480-9)=12 \times 471$ 组,每组 1 个 观测值,即第 9 个观测项 PM2.5。
-
然后计算每个特征的均值和标准差,再对每一个特征进行标准化处理。
标准化: $$ \hat{x_{i,j}}=\frac{x_{i,j}-\overline{x_{j}}}{\sigma_j} $$ 对特征进行标准化处理可以使标准化后的特征的均值和方差变为 0
# 读取训练数据集
data = pd.read_csv('./train.csv')
# 处理数据,将 NR 替换为 0,并将数据转换为 numpy 数组
# 只选取有用的数据列 (从第四列开始)
data = data.iloc[:, 3:]
data[data == 'NR'] = 0
raw_data = data.to_numpy()
# 将数据按月份分割成 12 组,每个月有 18 行传感器数据,每行有 480 小时的数据
month_data = {}
for month in range(12):
sample = np.empty([18, 480])
for day in range(20):
sample[:, day * 24: (day + 1) * 24] = raw_data[18 * (20 * month + day): 18 * (20 * month + day + 1), :]
month_data[month] = sample
# 构造训练数据 x 和标签数据 y,x 代表 9 小时的特征数据,y 代表第 10 小时的 PM2.5 数据
x = np.empty([12 * 471, 18 * 9], dtype=float)
y = np.empty([12 * 471, 1], dtype=float)
for month in range(12):
for day in range(20):
for hour in range(24):
if day == 19 and hour > 14: # 最后一天只取到第 15 小时
continue
x[month * 471 + day * 24 + hour, :] = month_data[month][:, day * 24 + hour: day * 24 + hour + 9].reshape(1, -1)
y[month * 471 + day * 24 + hour, 0] = month_data[month][9, day * 24 + hour + 9] # 预测第 10 小时 PM2.5 值
mean_x = np.mean(x, axis=0) # 计算每个特征的均值
std_x = np.std(x, axis=0) # 计算每个特征的标准差
# 对特征数据 x 进行标准化处理
for i in range(len(x)):
for j in range(len(x[0])):
if std_x[j] != 0: # 避免除以零
x[i][j] = (x[i][j] - mean_x[j]) / std_x[j]
3. 训练模型
I. 模型定义
$$ \hat{y}=X \cdot w $$
其中 $X$ 是特征矩阵,$w$ 是参数向量,$\hat{y}$ 是预测值
II. 损失函数
在训练过程中,我们使用**均方根误差(Root Mean Squared Error, RMSE)**作为损失函数来衡量模型的好坏。
RMSE表达式: $$ Loss=\sqrt{\frac{1}{N}\sum_{i=1}^{N}(\hat{y_i}-y_i)^2} $$ 其中:
-
$N$ 表示样本数。
-
$\hat{y_i}$ 表示模型预测的第 $i$ 个样本的预测值。
-
$y_i$ 表示第 $i$ 个样本的真实值。
-
$Loss$ 值越小表示模型的预测结果越接近真实值。
III. 梯度下降和 Adagrad 更新算法
-
梯度下降:
- 线性回归使用梯度下降算法来最小化损失函数。
- 梯度计算公式:
$$ grad=2X^T(Xw-y) $$
-
Adagrad 更新算法:
- Adagrad(自适应梯度算法),该算法可以自适应地调整学习率。
- Adagrad 累计梯度平方:
$$ G_t=G_{t-1}+grad^2 $$
其中 $G_t$ 是累计梯度平方,用于存储从开始到现在的梯度平方和。
- 权重更新公式(Adagrad):
$$ w=w-\frac{\alpha}{\sqrt{G_t+\epsilon}}\cdot grad $$
其中 $\alpha$ 是学习率,$\epsilon$ 是一个很小的值,用于避免除以 0。
IV. 代码实现
# 划分训练集和验证集,80% 作为训练集,20% 作为验证集
import math
x_train_set = x[:math.floor(len(x) * 0.8), :]
y_train_set = y[:math.floor(len(y) * 0.8), :]
x_validation = x[math.floor(len(x) * 0.8):, :]
y_validation = y[math.floor(len(y) * 0.8):, :]
print(len(x_train_set))
print(len(y_train_set))
print(len(x_validation))
print(len(y_validation))
# 特征维度为 18 * 9,加上偏置项 w_0
dim = 18 * 9 + 1
w = np.zeros([dim, 1]) # 初始化权重为 0
x_train_set = np.concatenate((np.ones([len(x_train_set), 1]), x_train_set), axis=1).astype(float) # 添加偏置项,x_train_set 的第一列为 1
x_validation = np.concatenate((np.ones([len(x_validation), 1]), x_validation), axis=1).astype(float) # 添加偏置项,x_validation 的第一列为 1
learning_rates = [10,50,100,200] # 学习率
iter_time = 1000 # 迭代次数
adagrad = np.zeros([dim, 1]) # Adagrad 累积梯度平方
eps = 1e-10 # 避免除以零
loss_list=[]
loss_list_dict={}
# 训练模型,使用 Adagrad 方法更新参数
for learning_rate in learning_rates:
for t in range(iter_time):
loss = np.sqrt(np.sum((np.dot(x_train_set, w) - y_train_set) ** 2) / len(y_train_set)) # 计算 RMSE 损失
print(str(t) + ":" + str(loss))
loss_list.append(loss)
gradient = 2 * np.dot(x_train_set.T, (np.dot(x_train_set, w) - y_train_set)) # 计算梯度
adagrad += gradient ** 2
w = w - learning_rate * gradient / np.sqrt(adagrad + eps) # 更新权重
loss_list_dict[learning_rate]=loss_list
loss_list=[]
np.save(f'weight{learning_rate}.npy', w) # 保存模型参数
w=np.zeros([dim,1]) # 重新初始化权重
adagrad=np.zeros([dim,1]) # 重新初始化累积梯度平方
V. 保存参数和结果
- 将预测结果写入文件,文件格式为
submit_learning_rate{learning_rate}.csv,同时要处理预测结果为负值的情况,将负值替换为 0 。
# 将预测结果写入文件
if learning_rate==0.2:
with open(f'submit.csv', mode='w') as submit_file:
submit_file.write('id,value\n')
for i in range(240):
# 由于预测结果可能为负数,将负数转换为 0
if (predictions[i][0] >= 0):
submit_file.write(f'id_{i},{predictions[i][0]}\n')
else:
submit_file.write(f'id_{i},0.00\n')
- 保存权重参数。
np.save(f'weight_learning_rate{learning_rate}.npy', w) # 保存模型参数
4. 算法评估
I. 参数设置
选取学习率(Learning rate)为 [0.01,0.05,0.1,0.2,0.3],迭代次数(iteration)设为40000
II. 绘制关系曲线
绘制不同的学习率下,迭代次数和损失率之间的关系曲线:
import matplotlib.pyplot as plt # 用于绘制图像
plt.figure(figsize=(10,6))
colors=['r','g','b','y','c','m','k','w']
plt.ylim(0,30)
plt.xlim(0,iter_time)
for i, learning_rate in enumerate(learning_rates):
plt.plot(range(iter_time),loss_list_dict[learning_rate],colors[i],label='learning rate = '+str(learning_rate))
plt.xlabel('iterations')
plt.ylabel('loss')
plt.legend() # 添加图例
plt.grid()
plt.show()
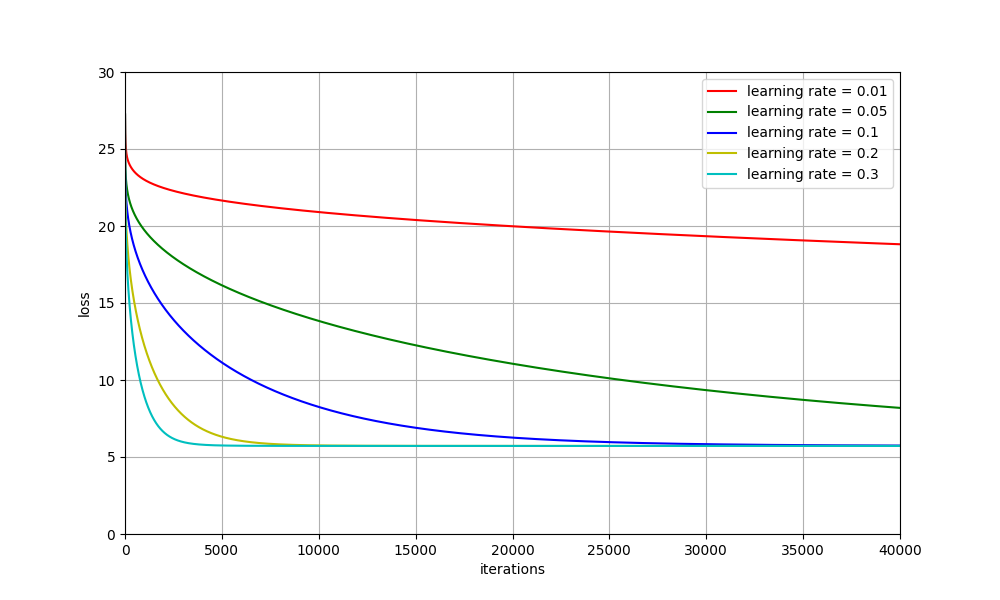
从曲线上可以看出:
- 学习率为 0.01 时,损失率(Loss)较大,而且曲线不够平滑。
- 学习率为 0.05 和 0.1 时,损失率下降的速度太慢,学习速度较慢。
- 学习率为 0.2 时,曲线较为平滑,而且平稳后的 Loss 值较低。
- 学习率为 0.3 时,曲线下降的速度较快,适合迭代次数较少的情况。
因此学习率选取为 0.2 较好,曲线平滑且损失率较低。
5. 算法优化
I. 正则化
使用正则化防止过拟合
-
L2 正则化(Ridge Regression):
- 在损失函数中加入 L2 正则化项,可以防止模型对训练数据的过度拟合。这样做可以惩罚权重过大的情况,使得模型更加平滑。
- 损失函数:
$$ Loss=\sqrt{\frac{1}{N}\sum_{i=1}^{N}(\hat{y_i}-y_i)^2}+\lambda \sum_{i=1}^{N}w_i^2 $$
其中$\lambda$ 为正则化强度。
- 更新权重:
$$ grad=grad+2\lambda w $$
-
L1 正则化(Lasso Regression):
-
使用 L1 正则化可以实现特征选择,可以减小模型复杂度,防止过拟合。
-
正则化项:
$$ \lambda \sum_{i=1}^N|w_i| $$
-
II. 正则化代码实现
设置学习率为 0.2,迭代次数为 20000,lambdaL1=0.0005,lambda_L2=0.0005
learning_rate = 0.2 # 学习率
iter_time = 20000 # 迭代次数
# 正则化参数
lambda_l1 = 0.0005 # L1 正则化系数
lambda_l2 = 0.0005 # L2 正则化系数
loss_list = []
validation_loss_list = []
# 训练模型,使用 L1 和 L2 正则化的 Adagrad 方法更新参数
for t in range(iter_time):
# 计算训练集损失 (RMSE)
loss = np.sqrt(np.sum((np.dot(x_train_set, w) - y_train_set) ** 2) / len(y_train_set))
# 添加 L1 和 L2 正则化项到损失函数中
loss += lambda_l1 * np.sum(np.abs(w)) + lambda_l2 * np.sum(w ** 2)
validation_loss = np.sqrt(np.sum((np.dot(x_validation, w) - y_validation) ** 2) / len(y_validation))
validation_loss_list.append(validation_loss)
loss_list.append(loss)
# 计算梯度
gradient = 2 * np.dot(x_train_set.T, (np.dot(x_train_set, w) - y_train_set))
# 添加 L1 正则化梯度
gradient += lambda_l1 * np.sign(w)
# 添加 L2 正则化梯度
gradient += 2 * lambda_l2 * w
# 使用 Adagrad 更新参数
adagrad += gradient ** 2
w = w - learning_rate * gradient / np.sqrt(adagrad + eps)
III. 绘制曲线
绘制训练集和验证集的 Loss 曲线,如下所示:
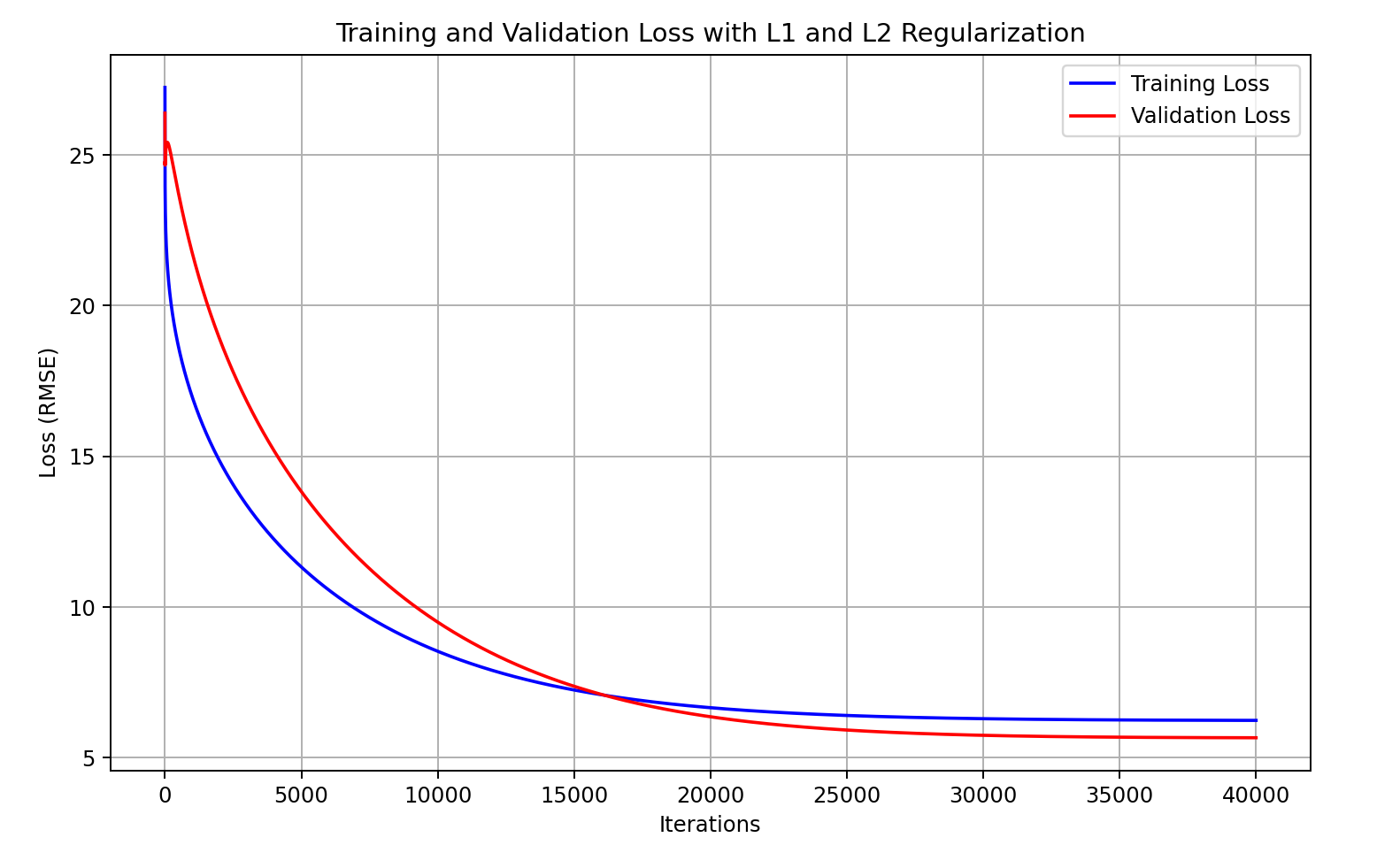
- 收敛趋势正常
- 训练集和验证集的损失接近
- 平稳期的损失率较低
五、实验结果
实验结果保存在了submit.csv中,预测了 1-12 月每个月最后 10 天第 10 小时的 PM2.5 数值,如下所示:
六、实验总结
在本次实验中,成功地使用线性回归模型预测了 PM2.5 的数值。通过对数据的清洗和特征提取,使用训练集 train.csv 中的特征成功拟合出线性回归模型,并在验证集上进行了验证,最后使用了 test.csv 进行了预测。验证了线性回归模型在 PM2.5 预测中的应用效果。但是实验中使用的线性模型比较简单,难以适应空气质量等复杂的、非线性波动的数据,预测值可能与实际值之间存在较大偏差。
七、附录
- 线性回归代码
lr.py
from kaggle.api.kaggle_api_extended import KaggleApi
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
# 读取训练数据集
data = pd.read_csv('./train.csv')
# 处理数据,将 NR 替换为 0,并将数据转换为 numpy 数组
# 只选取有用的数据列 (从第四列开始)
data = data.iloc[:, 3:]
data[data == 'NR'] = 0
raw_data = data.to_numpy()
# 将数据按月份分割成 12 组,每个月有 18 行传感器数据,每行有 480 小时的数据
month_data = {}
for month in range(12):
sample = np.empty([18, 480])
for day in range(20):
sample[:, day * 24: (day + 1) * 24] = raw_data[18 * (20 * month + day): 18 * (20 * month + day + 1), :]
month_data[month] = sample
# 构造训练数据 x 和标签数据 y,x 代表 9 小时的特征数据,y 代表第 10 小时的 PM2.5 数据
x = np.empty([12 * 471, 18 * 9], dtype=float)
y = np.empty([12 * 471, 1], dtype=float)
for month in range(12):
for day in range(20):
for hour in range(24):
if day == 19 and hour > 14: # 最后一天只取到第 15 小时
continue
x[month * 471 + day * 24 + hour, :] = month_data[month][:, day * 24 + hour: day * 24 + hour + 9].reshape(1, -1)
y[month * 471 + day * 24 + hour, 0] = month_data[month][9, day * 24 + hour + 9] # 预测第 10 小时 PM2.5 值
# 对特征数据 x 进行标准化处理
mean_x = np.mean(x, axis=0) # 计算每个特征的均值
std_x = np.std(x, axis=0) # 计算每个特征的标准差
#
for i in range(len(x)):
for j in range(len(x[0])):
if std_x[j] != 0: # 避免除以零
x[i][j] = (x[i][j] - mean_x[j]) / std_x[j]
# 划分训练集和验证集,80% 作为训练集,20% 作为验证集
import math
x_train_set = x[:math.floor(len(x) * 0.8), :]
y_train_set = y[:math.floor(len(y) * 0.8), :]
x_validation = x[math.floor(len(x) * 0.8):, :]
y_validation = y[math.floor(len(y) * 0.8):, :]
# 打印训练集和验证集的维度
print(len(x_train_set))
print(len(y_train_set))
print(len(x_validation))
print(len(y_validation))
# 读取测试数据并进行预处理
testdata = pd.read_csv('./test.csv', header=None)
test_data = testdata.iloc[:, 2:]
#test_data[test_data == 'NR'] = 0
test_data = test_data.replace('NR', 0)
test_data = test_data.to_numpy()
# 构造测试数据集 test_x
test_x = np.empty([240, 18 * 9], dtype=float)
for i in range(240):
test_x[i, :] = test_data[18 * i: 18 * (i + 1), :].reshape(1, -1)
for i in range(len(test_x)):
for j in range(len(test_x[0])):
if std_x[j] != 0:
test_x[i][j] = (test_x[i][j] - mean_x[j]) / std_x[j]
test_x = np.concatenate((np.ones([240, 1]), test_x), axis=1).astype(float) # 添加偏置项
# 初始化线性回归模型的参数
# 特征维度为 18 * 9,加上偏置项 w_0
dim = 18 * 9 + 1
w = np.zeros([dim, 1]) # 初始化权重为 0
x_train_set = np.concatenate((np.ones([len(x_train_set), 1]), x_train_set), axis=1).astype(float) # 添加偏置项,x_train_set 的第一列为 1
x_validation = np.concatenate((np.ones([len(x_validation), 1]), x_validation), axis=1).astype(float) # 添加偏置项,x_validation 的第一列为 1
learning_rates = [0.05,0.1,0.2,0.3] # 学习率列表
iter_time = 20000 # 迭代次数
adagrad = np.zeros([dim, 1]) # Adagrad 累积梯度平方
eps = 1e-10 # 避免除以零
loss_list=[] # 训练集损失列表
validation_loss_list=[] # 验证集损失列表
loss_list_dict={} # 训练集损失字典
validation_loss_list_dict={} # 验证集损失字典
# 训练模型,使用 Adagrad 方法更新参数
print('\033[31m---------Training...---------\033[32m')
for learning_rate in learning_rates:
print('learning rate = '+str(learning_rate))
for t in tqdm(range(iter_time)):
loss = np.sqrt(np.sum((np.dot(x_train_set, w) - y_train_set) ** 2) / len(y_train_set)) # 计算 RMSE 损失
validation_loss = np.sqrt(np.sum((np.dot(x_validation, w) - y_validation) ** 2) / len(y_validation))
validation_loss_list.append(validation_loss)
# print(str(t) + ":" + str(loss))
loss_list.append(loss)
gradient = 2 * np.dot(x_train_set.T, (np.dot(x_train_set, w) - y_train_set)) # 计算梯度
adagrad += gradient ** 2
w = w - learning_rate * gradient / np.sqrt(adagrad + eps) # 更新权重
# 预测测试数据
predictions = np.dot(test_x, w)
# 将预测结果写入文件
if learning_rate==0.2:
with open(f'submit.csv', mode='w') as submit_file:
submit_file.write('id,value\n')
for i in range(240):
# 由于预测结果可能为负数,将负数转换为 0
if (predictions[i][0] >= 0):
submit_file.write(f'id_{i},{predictions[i][0]}\n')
else:
submit_file.write(f'id_{i},0.00\n')
loss_list_dict[learning_rate]=loss_list
validation_loss_list_dict[learning_rate]=validation_loss_list
loss_list=[]
validation_loss_list=[]
np.save(f'weight_learning_rate{learning_rate}.npy', w) # 保存模型参数
w=np.zeros([dim,1]) # 重新初始化权重
adagrad=np.zeros([dim,1]) # 重新初始化累积梯度平方
print('\033[34m---------Done!---------\033[0m')
plt.figure(figsize=(10,6))
colors=['r','g','b','y','c','m','k','w']
plt.ylim(0,30)
plt.xlim(0,iter_time)
for i, learning_rate in enumerate(learning_rates):
plt.plot(range(iter_time),loss_list_dict[learning_rate],colors[i],label='learning rate = '+str(learning_rate))
plt.xlabel('iterations')
plt.ylabel('loss')
plt.legend() # 添加图例
plt.grid()
plt.title('Training Loss')
plt.savefig('Loss.png')
plt.show()
- 使用正则化优化后的线性回归代码
lr_L1L2.py:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
# 读取训练数据集
data = pd.read_csv('./train.csv')
# 处理数据,将 NR 替换为 0,并将数据转换为 numpy 数组
# 只选取有用的数据列 (从第四列开始)
data = data.iloc[:, 3:]
data[data == 'NR'] = 0
raw_data = data.to_numpy()
# 将数据按月份分割成 12 组,每个月有 18 行传感器数据,每行有 480 小时的数据
month_data = {}
for month in range(12):
sample = np.empty([18, 480])
for day in range(20):
sample[:, day * 24: (day + 1) * 24] = raw_data[18 * (20 * month + day): 18 * (20 * month + day + 1), :]
month_data[month] = sample
# 构造训练数据 x 和标签数据 y,x 代表 9 小时的特征数据,y 代表第 10 小时的 PM2.5 数据
x = np.empty([12 * 471, 18 * 9], dtype=float)
y = np.empty([12 * 471, 1], dtype=float)
for month in range(12):
for day in range(20):
for hour in range(24):
if day == 19 and hour > 14: # 最后一天只取到第 15 小时
continue
x[month * 471 + day * 24 + hour, :] = month_data[month][:, day * 24 + hour: day * 24 + hour + 9].reshape(1, -1)
y[month * 471 + day * 24 + hour, 0] = month_data[month][9, day * 24 + hour + 9] # 预测第 10 小时 PM2.5 值
# 对特征数据 x 进行标准化处理
mean_x = np.mean(x, axis=0) # 计算每个特征的均值
std_x = np.std(x, axis=0) # 计算每个特征的标准差
# 标准化特征数据
for i in range(len(x)):
for j in range(len(x[0])):
if std_x[j] != 0: # 避免除以零
x[i][j] = (x[i][j] - mean_x[j]) / std_x[j]
# 划分训练集和验证集,80% 作为训练集,20% 作为验证集
import math
x_train_set = x[:math.floor(len(x) * 0.8), :]
y_train_set = y[:math.floor(len(y) * 0.8), :]
x_validation = x[math.floor(len(x) * 0.8):, :]
y_validation = y[math.floor(len(y) * 0.8):, :]
# 初始化线性回归模型的参数
# 特征维度为 18 * 9,加上偏置项 w_0
dim = 18 * 9 + 1
w = np.zeros([dim, 1]) # 初始化权重为 0
x_train_set = np.concatenate((np.ones([len(x_train_set), 1]), x_train_set), axis=1).astype(float) # 添加偏置项,x_train_set 的第一列为 1
x_validation = np.concatenate((np.ones([len(x_validation), 1]), x_validation), axis=1).astype(float) # 添加偏置项,x_validation 的第一列为 1
learning_rate = 0.2 # 学习率
iter_time = 20000 # 迭代次数
adagrad = np.zeros([dim, 1]) # Adagrad 累积梯度平方
eps = 1e-10 # 避免除以零
# 正则化参数
lambda_l1 = 0.0005 # L1 正则化系数
lambda_l2 = 0.0005 # L2 正则化系数
loss_list = []
validation_loss_list = []
# 训练模型,使用 L1 和 L2 正则化的 Adagrad 方法更新参数
for t in tqdm(range(iter_time)):
# 计算训练集损失 (RMSE)
loss = np.sqrt(np.sum((np.dot(x_train_set, w) - y_train_set) ** 2) / len(y_train_set))
# 添加 L1 和 L2 正则化项到损失函数中
loss += lambda_l1 * np.sum(np.abs(w)) + lambda_l2 * np.sum(w ** 2)
validation_loss = np.sqrt(np.sum((np.dot(x_validation, w) - y_validation) ** 2) / len(y_validation))
validation_loss_list.append(validation_loss)
loss_list.append(loss)
# 计算梯度
gradient = 2 * np.dot(x_train_set.T, (np.dot(x_train_set, w) - y_train_set))
# 添加 L1 正则化梯度
gradient += lambda_l1 * np.sign(w)
# 添加 L2 正则化梯度
gradient += 2 * lambda_l2 * w
# 使用 Adagrad 更新参数
adagrad += gradient ** 2
w = w - learning_rate * gradient / np.sqrt(adagrad + eps)
# 绘制训练集和验证集的损失曲线
plt.figure(figsize=(10, 6))
plt.plot(range(iter_time), loss_list, 'b', label='Training Loss')
plt.plot(range(iter_time), validation_loss_list, 'r', label='Validation Loss')
plt.xlabel('Iterations')
plt.ylabel('Loss (RMSE)')
plt.legend() # 添加图例
plt.grid()
plt.title('Training and Validation Loss with L1 and L2 Regularization')
plt.savefig('loss_l1l2.png')
plt.show()